

Ferramenta aberta busca medir exatidão de respostas da inteligência artificial
Disponível para uso público, banco de dados HLE reúne informações sobre diversas áreas do conhecimento para testar eficiência de modelos de IA



Pesquisadores de todo o mundo, com participação brasileira, criaram um banco de dados avançado para testar com alta precisão os sistemas de inteligência artificial (IA), o Humanity’s Last Exam (HLE, sigla em inglês para Último Exame da Humanidade). A ferramenta reúne questões sobre diversas áreas do conhecimento humano, como ciências naturais e matemática, usadas para medir a capacidade de resposta dos modelos de IA. O HLE, que está disponível para uso público, tem seu funcionamento descrito em artigo publicado na revista Nature.
“A ideia é essencialmente criar uma ferramenta para medir o avanço dos modelos de IA de hoje”, explica a pesquisadora Emily de Oliveira Santos, do Instituto de Ciências Matemáticas e da Computação (ICMC) da USP, em São Carlos, que contribuiu com o desenvolvimento do HLE. “Por exemplo, quando uma desenvolvedora de IAs para propósito geral, como a OpenAI com o ChatGPT, anuncia um modelo novo, ela costuma tabelar a performance do modelo em uma série de benchmarks como o SWE-Bench, GPQA Diamond, FrontierMath e agora também o HLE.”
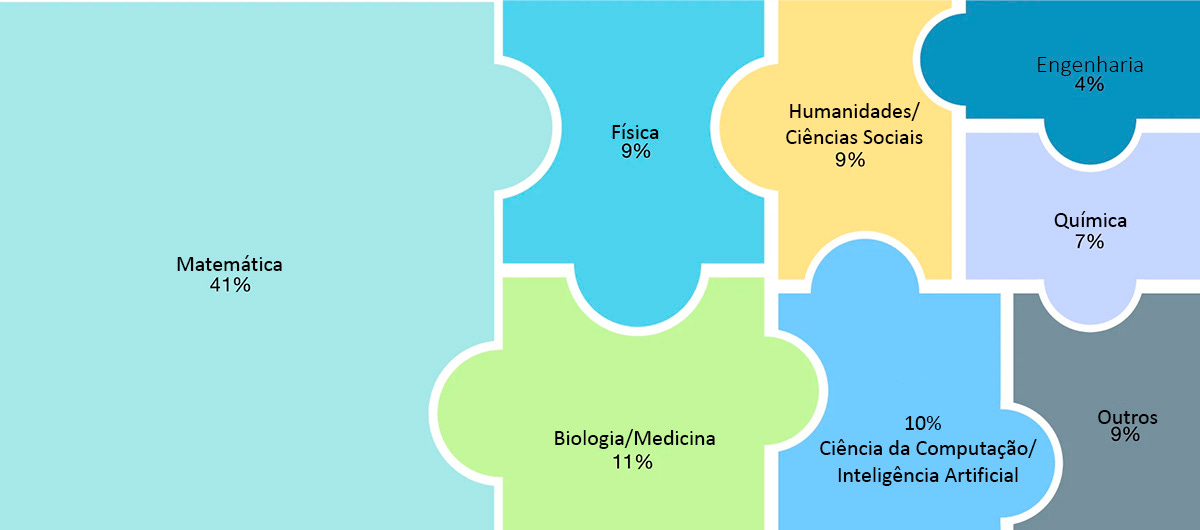
“Benchmarks são coletâneas de problemas e, mais recentemente, tarefas, que buscam testar as capacidades de um dado modelo. A proposta original do HLE é essencialmente criar o ‘benchmark supremo’, um teste onde tirar próximo a 100% seria equivalente a conseguir fazer qualquer coisa que um ser humano faz”, afirma a pesquisadora. “Conforme novos modelos de IA forem sendo desenvolvidos e lançados, vamos poder saber o quão melhor eles estão ficando usando o HLE e outros benchmarks.” O HLE reúne 2.500 questões em dezenas de assuntos, incluindo matemática, humanidades e ciências naturais.
De acordo com Emily Santos, o HLE é um benchmark com resposta final unicamente determinada e fácil de verificar. “Isso significa que todas as respostas são objetivas e únicas, quer dizer, dois especialistas em um determinado assunto chegariam exatamente numa mesma resposta correta”, relata. “As respostas costumam ser um número inteiro ou algo que é igualmente fácil de verificar.”
Teste de habilidades
“Na prática, você pode criar um script, um programa de computador que vai rodar os modelos de IA, como o LLM, nos problemas do benchmark usando uma instrução padronizada.” LLM é a sigla em inglês para Modelo de Linguagem Grande (Large Language Model), uma IA projetada para processar, compreender e gerar texto de maneira semelhante à inteligência humana. “Desse modo, você pode extrair a resposta final do texto que o LLM gera e checar se a porcentagem das respostas bateram com as respostas corretas, e ao final disso você sabe o quão bem, ou o quão mal, o LLM foi no teste.”
Segundo a pesquisadora, como o HLE é um benchmark diverso, ele vai testar uma variedade bem grande de habilidades em geral. “Muitas dessas são em áreas científicas, mas algumas também são sobre conhecimentos diversos”, afirma. “Ele tem potencial para avaliar coisas básicas como senso comum e conhecimento geral do mundo, por exemplo, perguntas sobre a história da humanidade.”
“O HLE também pode testar a agência, que seria a capacidade de fazer ações no mundo. Uma das perguntas, entre outras, é fazer um origami de tsuru, uma dobradura representando um pássaro, desmontar, e depois contar em quantas áreas o papel foi particionado por causa das dobras”, diz Emily de Oliveira Santos. “Por fim, outro uso é em áreas específicas do conhecimento e nas capacidades de raciocínio que permitem a sua aplicação, como a equação de Schrödinger em mecânica quântica e a forma de usá-la para calcular propriedades de sistemas quânticos.”
O HLE foi disponibilizado no site https://lastexam.ai para subsidiar pesquisas e políticas públicas a partir do entendimento das capacidades dos modelos de IA. O artigo A benchmark of expert-level academic questions to assess AI capabilities foi publicado na revista Nature em janeiro, assinado pelo Center of AI Safety, Scale AI, em São Francisco (Estados Unidos) e pelo HLE Contribuitors Consortium, que reúne pesquisadores de mais de 40 países que contribuíram no desenvolvimento do projeto. No ICMC, a pesquisa teve a colaboração de Emily de Oliveira Santos, Felipe Meneguitti Dias e Benedito Alves de Oliveira Junior.
Matéria: Júlio Bernardes | Jornal da USP